Управление данными
Развертывания ClickHouse для мониторинга неизменно связаны с большими наборами данных, которые необходимо управлять. ClickHouse предлагает ряд функций для помощи в управлении данными.
Партиции
Партиционирование в ClickHouse позволяет логически разделить данные на диске в зависимости от колонки или SQL-выражения. Логическое разделение данных позволяет управлять каждой партицией независимо, например, удалять. Это позволяет пользователям эффективно перемещать партиции, а следовательно, подмножества, между уровнями хранения в зависимости от времени или истекать данные/эффективно удалять из кластера.
Партиционирование задается в таблице при её первоначальном определении с помощью инструкции PARTITION BY. Эта инструкция может содержать SQL-выражение по любым колонкам, результаты которого определяют, в какую партицию будет отправлена строка.
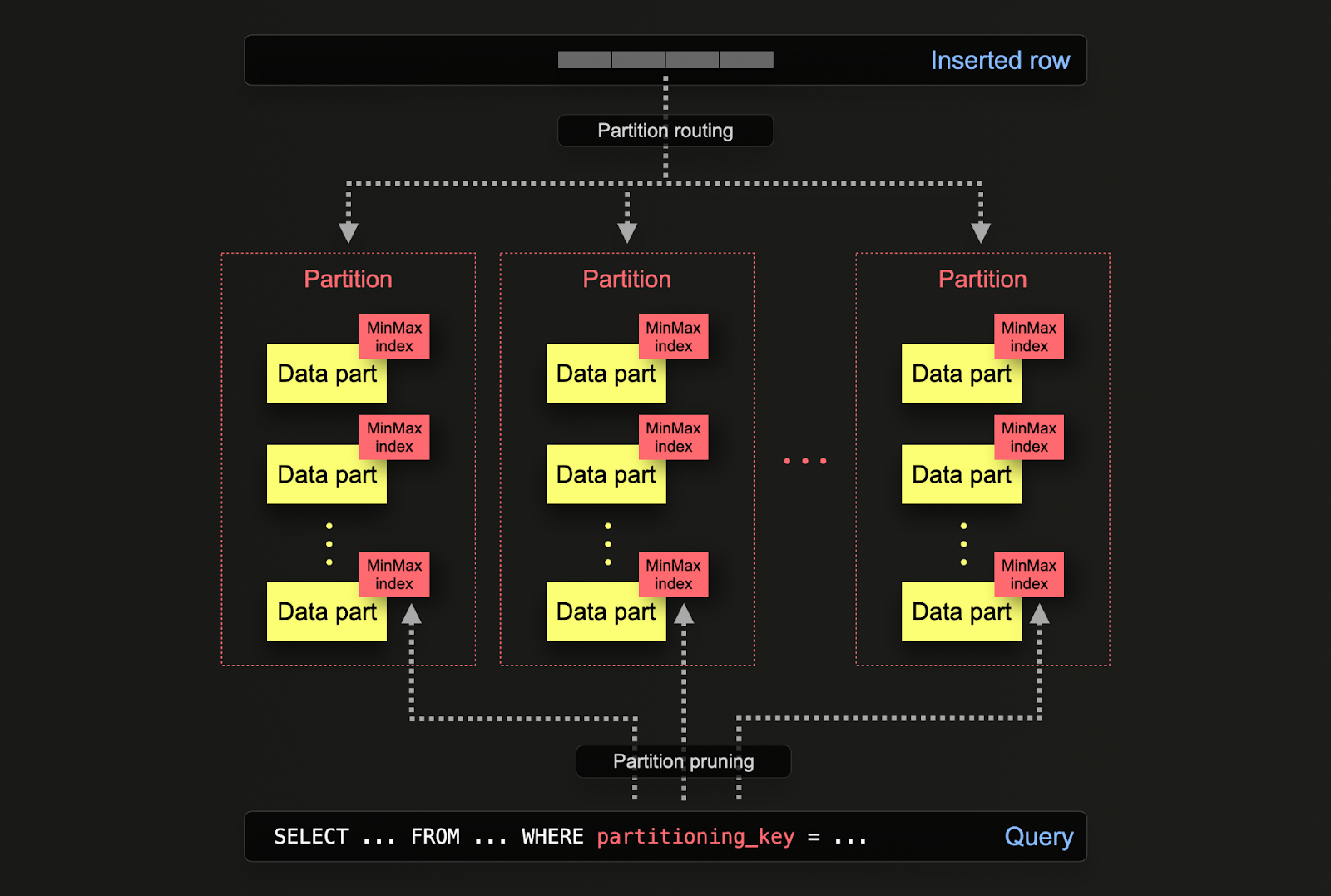
Части данных логически связаны (через общий префикс имени папки) с каждой партицией на диске и могут запрашиваться изолированно. На приведённом ниже примере схема по умолчанию otel_logs партиционируется по дням, используя выражение toDate(Timestamp). Когда строки вставляются в ClickHouse, это выражение будет оцениваться для каждой строки и перенаправляться в соответствующую партицию, если она существует (если строка является первой за день, партиция будет создана).
С помощью некоторых операций можно выполнять операции с партициями, включая резервное копирование, манипуляции с колонками, мутации изменения/удаления данных по строкам и очистку индексов (например, вторичных индексов).
В качестве примера, предположим, что наша таблица otel_logs партиционирована по дням. Если она будет заполнена структурированным набором данных журналов, то будет содержать данные за несколько дней:
Текущие партиции можно найти с помощью простого запроса к системной таблице:
У нас также может быть другая таблица, otel_logs_archive, которую мы используем для хранения старых данных. Данные могут быть эффективно перемещены в эту таблицу по партициям (это просто изменение метаданных).
Это в отличие от других техник, которые требуют использования INSERT INTO SELECT и переписывания данных в новую целевую таблицу.
Перемещение партиций между таблицами требует выполнения нескольких условий, в том числе таблицы должны иметь одинаковую структуру, ключ партиционирования, первичный ключ и индексы/проекции. Подробные примечания о том, как указывать партиции в DDL ALTER, можно найти здесь.
Кроме того, данные могут быть эффективно удалены по партициям. Это гораздо более ресурсосберегающе, чем альтернативные техники (мутации или легковесные удаления) и должно быть предпочтительным.
Эта функция используется TTL, когда настройка ttl_only_drop_parts=1 используется. См. Управление данными с помощью TTL для получения дополнительных сведений.
Применения
Выше показано, как данные могут быть эффективно перемещены и манипулированы по партициям. На практике пользователи, вероятно, будут чаще всего использовать операции с партициями в сценариях мониторинга для двух случаев:
- Многоуровневая архитектура - Перемещение данных между уровнями хранения (см. Уровни хранения), что позволяет строить архитектуры горячего и холодного хранения.
- Эффективное удаление - когда данные достигают заданного TTL (см. Управление данными с помощью TTL)
Ниже мы подробно рассматриваем оба этих аспекта.
Производительность запросов
Хотя партиции могут помочь с производительностью запросов, это зависит в значительной степени от паттернов доступа. Если запросы нацелены только на несколько партиций (в идеале одну), производительность потенциально может улучшиться. Это обычно полезно только в том случае, если ключ партиционирования не является частью первичного ключа и вы фильтруете по нему. Однако запросы, которым нужно охватывать много партиций, могут работать хуже, чем если бы партиционирование не использовалось (поскольку может быть больше частей). Преимущество нацеливания на одну партицию будет еще менее заметным или даже отсутствующим, если ключ партиционирования уже является ранним элементом первичного ключа. Партиционирование также можно использовать для оптимизации запросов GROUP BY, если значения в каждой партиции уникальны. Однако в общем пользователи должны убедиться, что первичный ключ оптимизирован и рассматривать партиционирование как метод оптимизации запросов в исключительных случаях, когда паттерны доступа затрагивают определённое предсказуемое подмножество данных, например, партиционирование по дням, когда большинство запросов касается последнего дня. См. здесь для примера такого поведения.
Управление данными с помощью TTL (время жизни)
Время жизни (TTL) является ключевой функцией в решениях мониторинга на базе ClickHouse для эффективного хранения и управления данными, особенно учитывая огромные объемы данных, которые постоянно генерируются. Реализация TTL в ClickHouse позволяет автоматически удалять и истекать старые данные, что гарантирует оптимальное использование хранилища и поддержание производительности без ручного вмешательства. Эта возможность необходима для того, чтобы база данных оставалась компактной, снижая затраты на хранение, и обеспечивала быстрое и эффективное выполнение запросов за счет фокуса на наиболее актуальных и свежих данных. Более того, это помогает обеспечить соответствие политикам хранения данных, систематически управляя жизненным циклом данных, тем самым повышая общую устойчивость и масштабируемость решения для мониторинга.
TTL может быть указан как на уровне таблицы, так и на уровне колонки в ClickHouse.
TTL на уровне таблицы
Схема по умолчанию как для журналов, так и для трассировок включаетTTL для истечения данных после заданного периода. Это указывается в экспортере ClickHouse под ключом ttl, например:
Этот синтаксис в настоящее время поддерживает синтаксис времени длительности Golang. Мы рекомендуем пользователям использовать h и убедиться, что это соответствует периоду партиционирования. Например, если вы партиционируете по дням, убедитесь, что это кратное количество дней, например, 24h, 48h, 72h. Это автоматически добавит условие TTL к таблице, например, если ttl: 96h.
По умолчанию данные с истекшим TTL удаляются, когда ClickHouse объединяет части данных. Когда ClickHouse обнаруживает, что данные истекли, он выполняет внеплановое объединение.
TTLs не применяются немедленно, а следуют расписанию, как отмечалось выше. Настройка таблицы MergeTree merge_with_ttl_timeout устанавливает минимальную задержку в секундах перед повторным объединением с удалением TTL. Значение по умолчанию составляет 14400 секунд (4 часа). Но это только минимальная задержка, может пройти больше времени, пока не будет вызвано объединение TTL. Если значение слишком низкое, будут выполняться несколько внеплановых объединений, которые могут потреблять много ресурсов. С помощью команды ALTER TABLE my_table MATERIALIZE TTL можно принудительно вызвать истечение TTL.
Важно: Мы рекомендуем использовать настройку ttl_only_drop_parts=1 (применяется по умолчанию в схеме). Когда эта настройка включена, ClickHouse удаляет целую часть, когда все строки в ней истекают. Удаление целых частей вместо частичной очистки TTL-д строк (что достигается через ресурсоемкие мутации, когда ttl_only_drop_parts=0) позволяет сократить время merge_with_ttl_timeout и снизить влияние на производительность системы. Если данные партиционированы по тому же параметру, по которому вы выполняете истечение TTL, например, по дням, части будут естественным образом содержать только данные из определенного интервала. Это обеспечит эффективное применение ttl_only_drop_parts=1.
TTL на уровне колонок
Приведенный выше пример истекает данные на уровне таблицы. Пользователи также могут истекать данные на уровне колонок. По мере старения данных это можно использовать для удаления колонок, чьи значения в расследованиях не оправдывают их затраты на ресурсы. Например, мы рекомендуем сохранять колонку Body на случай, если будет добавлена новая динамическая метаинформация, которая не была извлечена во время вставки, например, новая метка Kubernetes. После определенного периода, например, 1 месяц, может стать очевидным, что эта дополнительная метаинформация не полезна - что снижает ценность сохранения колонки Body.
Ниже мы показываем, как колонка Body может быть удалена через 30 дней.
Указание TTL на уровне колонки требует, чтобы пользователи задали свою собственную схему. Это нельзя указать в OTel collector.
Повторное сжатие данных
Хотя мы обычно рекомендуем ZSTD(1) для наборов данных мониторинга, пользователи могут экспериментировать с различными алгоритмами сжатия или более высокими уровнями сжатия, например, ZSTD(3). Кроме того, сжатие можно настроить так, чтобы оно менялось после установленного периода. Это может быть уместно, если кодек или алгоритм сжатия улучшает сжатие, но приводит к ухудшению производительности запросов. Этот компромисс может быть приемлем для старых данных, которые запрашиваются реже, но не для последних данных, которые чаще используются в расследованиях.
Пример этого показан ниже, где мы сжимаем данные с использованием ZSTD(3) через 4 дня вместо их удаления.
Мы рекомендуем пользователям всегда оценивать влияние как на вставку, так и на производительность запроса разных уровней сжатия и алгоритмов. Например, дельта-кодеки могут быть полезны для сжатия временных меток. Однако, если они являются частью первичного ключа, производительность фильтрации может ухудшиться.
Дополнительные сведения и примеры по настройке TTL можно найти здесь. Примеры того, как TTL могут быть добавлены и изменены для таблиц и колонок, можно найти здесь. Для того, как TTL позволяет создавать иерархии хранения, такие как горячие и теплые архитектуры, см. Уровни хранения.
Уровни хранения
В ClickHouse пользователи могут создавать уровни хранения на различных дисках, например, горячие/недавние данные на SSD и более старые данные, хранящиеся на S3. Эта архитектура позволяет использовать менее дорогое хранилище для более старых данных, которые имеют более высокие требования к производительности запросов из-за их редкого использования в расследованиях.
ClickHouse Cloud использует одну копию данных, которая хранится на S3, с кэшем узлов на SSD. Уровни хранения в ClickHouse Cloud, следовательно, не требуются.
Создание уровней хранения требует от пользователей создания дисков, которые затем используются для формирования политик хранения с объемами, которые можно указать при создании таблицы. Данные могут автоматически перемещаться между дисками в зависимости от уровня заполнения, размеров частей и приоритетов объемов. Дополнительные сведения можно найти здесь.
Хотя данные могут перемещаться вручную между дисками с помощью команды ALTER TABLE MOVE PARTITION, перемещение данных между объемами также можно контролировать с помощью TTL. Полный пример можно найти здесь.
Управление изменениями схемы
Схемы журналов и трассировок неизменно будут изменяться на протяжении всего срока службы системы, например, когда пользователи мониторят новые системы, имеющие различные метаданные или метки подов. Создавая данные, используя схему OTel, и захватывая оригинальные события в структурированном формате, схемы ClickHouse будут устойчивы к этим изменениям. Однако, по мере появления новой метаинформации и изменения паттернов доступа к запросам, пользователи захотят обновить схемы, чтобы отразить эти изменения.
Чтобы избежать простоя во время изменений схемы, у пользователей есть несколько вариантов, которые мы представляем ниже.
Использование значений по умолчанию
Колонки могут быть добавлены в схему с использованием DEFAULT значений. Указанное значение по умолчанию будет использоваться, если оно не указано при INSERT.
Изменения схемы могут быть выполнены до изменения любой логики преобразования материализованного представления или настройки OTel collector, что вызывает отправку этих новых колонок.
После изменения схемы пользователи могут перенастроить OTel collectors. Предполагая, что пользователи используют рекомендованный процесс, описанный в "Извлечение структуры с помощью SQL", где OTel collectors отправляют свои данные в таблицу Null с материализованным представлением, ответственным за извлечение целевой схемы и отправку результатов в целевую таблицу для хранения, представление можно изменить с помощью синтаксиса ALTER TABLE ... MODIFY QUERY. Предположим, у нас есть целевая таблица ниже с её соответствующим материализованным представлением (аналогичным тому, что использовалось в "Извлечение структуры с помощью SQL") для извлечения целевой схемы из структурированных журналов OTel:
Предположим, что мы хотим извлечь новую колонку Size из LogAttributes. Мы можем добавить это в нашу схему с помощью ALTER TABLE, указав значение по умолчанию:
В приведённом примере мы указываем значение по умолчанию как ключ size в LogAttributes (это будет 0, если он не существует). Это означает, что запросы, которые обращаются к этой колонке для строк, у которых значение не было вставлено, должны получить доступ к Map и, следовательно, будут медленнее. Мы также можем легко указать это как константу, например, 0, что уменьшит стоимость последующих запросов к строкам, у которых нет значения. Запрос к этой таблице показывает, что значение заполняется, как и ожидалось, из Map:
Чтобы убедиться, что это значение вставляется для всех будущих данных, мы можем изменить наше материализованное представление, используя синтаксис ALTER TABLE, как показано ниже:
Последующие строки будут иметь колонку Size, заполненную во время вставки.
Создание новых таблиц
В качестве альтернативы приведенному выше процессу пользователи могут просто создать новую целевую таблицу с новой схемой. Любые материализованные представления можно затем изменить для использования новой таблицы с помощью ALTER TABLE MODIFY QUERY. С помощью этого подхода пользователи могут версионировать свои таблицы, например, otel_logs_v3.
Этот подход оставляет пользователям несколько таблиц для запросов. Чтобы выполнить запросы по таблицам, пользователи могут использовать функцию merge , которая принимает шаблоны с символами подстановки для имени таблицы. Мы демонстрируем это ниже, запрашивая таблицы v2 и v3 таблицы otel_logs:
Если пользователи хотят избежать использования функции merge и предоставить таблицу конечным пользователям, которая объединяет несколько таблиц, можно использовать движок свёртки. Мы демонстрируем это ниже:
Это можно обновить при добавлении новой таблицы, используя синтаксис таблицы EXCHANGE. Например, чтобы добавить таблицу v4, мы можем создать новую таблицу и атомарно обменяться ею с предыдущей версией.