Инкрементные Материализованные Представления
Инкрементные Материализованные Представления (Materialized Views) позволяют пользователям перенести стоимость вычислений с времени запроса на время вставки, что приводит к более быстрому выполнению запросов SELECT.
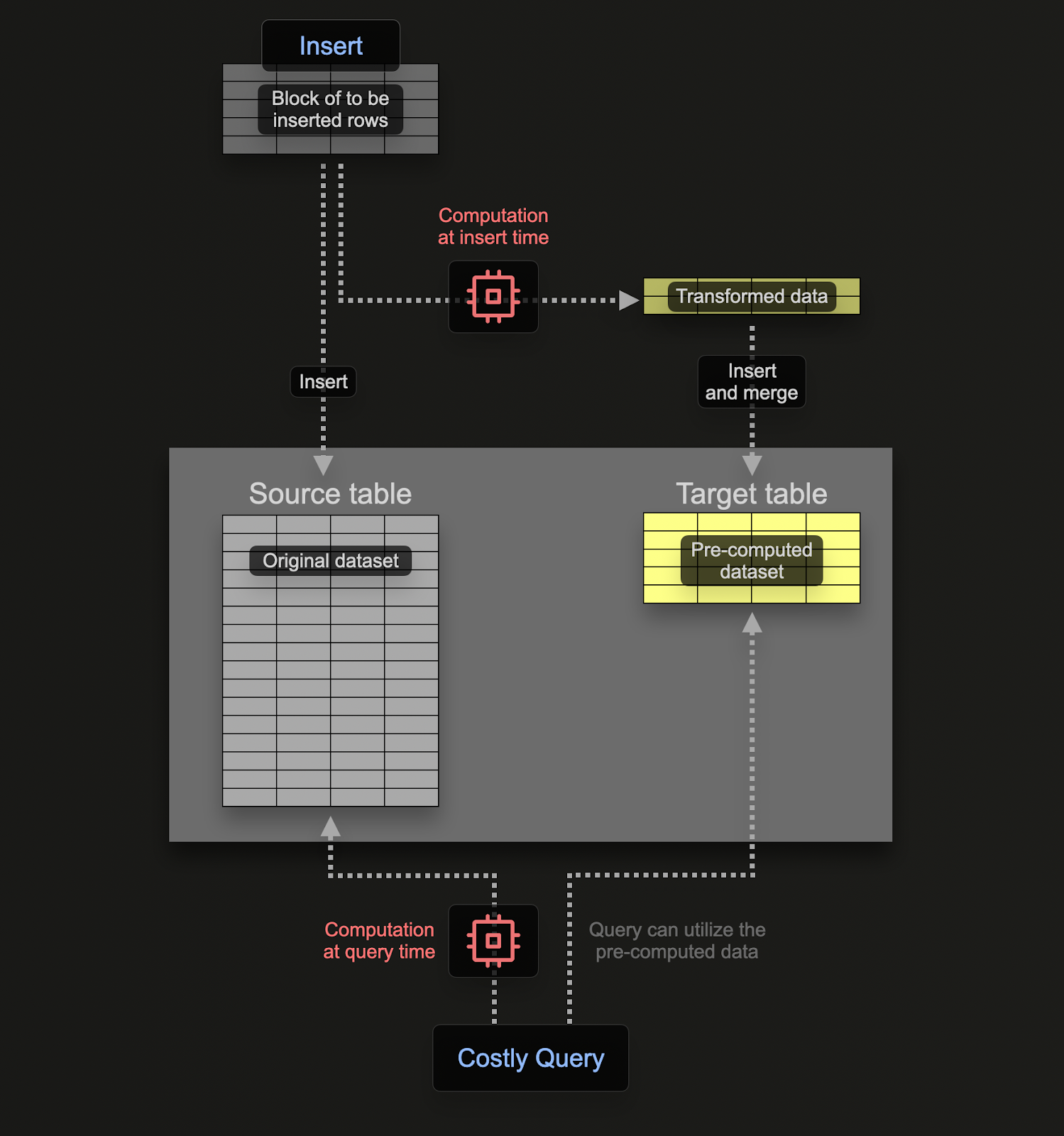
В отличие от транзакционных баз данных, таких как Postgres, материализованное представление в ClickHouse является просто триггером, который выполняет запрос к блокам данных по мере их вставки в таблицу. Результат этого запроса вставляется во вторую "целевую" таблицу. Если будут вставлены дополнительные строки, результаты снова будут отправлены в целевую таблицу, где промежуточные результаты будут обновлены и объединены. Этот объединенный результат эквивалентен выполнению запроса над всеми исходными данными.
Основная мотивация для материализованных представлений заключается в том, что результаты, вставляемые в целевую таблицу, представляют собой результаты агрегации, фильтрации или преобразования строк. Эти результаты часто будут меньшим представлением исходных данных (частичная выборка в случае агрегации). Это, наряду с тем, что конечный запрос для чтения результатов из целевой таблицы является простым, гарантирует время выполнения запросов быстрее, чем если бы те же вычисления выполнялись над исходными данными, переносит вычисления (а вместе с ними и задержку запросов) с времени запроса на время вставки.
Материализованные представления в ClickHouse обновляются в реальном времени по мере поступления данных в таблицу, на которой они основаны, функционируя больше как постоянно обновляемые индексы. Это в контрасте с другими базами данных, где материализованные представления обычно являются статичными снимками запроса, которые должны быть обновлены (похожие на обновляемые материализованные представления ClickHouse).
Пример
Предположим, мы хотим получить количество голосов "за" и "против" в день для поста.
Этот запрос достаточно прост в ClickHouse благодаря функции toStartOfDay:
Этот запрос уже быстрый благодаря ClickHouse, но можем ли мы сделать лучше?
Если мы хотим вычислить это время вставки с помощью материализованного представления, нам нужна таблица для получения результатов. Эта таблица должна хранить только 1 строку на день. Если поступает обновление для существующего дня, другие столбцы должны быть объединены с существующей строкой того дня. Для того чтобы произошло это объединение инкрементальных состояний, частичные состояния должны храниться для других столбцов.
Это требует специального типа движка в ClickHouse: SummingMergeTree. Он заменяет все строки с одинаковым ключом сортировки одной строкой, которая содержит сумма значений для числовых столбцов. Следующая таблица объединит любые строки с одной и той же датой, суммируя любые числовые столбцы:
Чтобы продемонстрировать наше материализованное представление, предположим, что наша таблица голосов пуста и еще не получила никаких данных. Наше материализованное представление выполняет вышеуказанный SELECT на данных, вставленных в votes, и результаты отправляются в up_down_votes_per_day:
Клаузula TO здесь имеет ключевое значение, указывая, куда будут отправлены результаты, т.е. в up_down_votes_per_day.
Мы можем восстановить нашу таблицу голосов из нашей предыдущей вставки:
По завершении мы можем подтвердить размер нашего up_down_votes_per_day - у нас должна быть 1 строка на день:
Мы эффективно снизили количество строк здесь с 238 миллионов (в votes) до 5000, храня результат нашего запроса. Ключевым здесь, однако, является то, что если новые голоса будут вставлены в таблицу votes, новые значения будут отправлены в up_down_votes_per_day за их соответствующий день, где они будут автоматически объединены асинхронно в фоновом режиме - сохраняя только одну строку на день. Таким образом, up_down_votes_per_day всегда будет как малым, так и актуальным.
Поскольку процесс объединения строк является асинхронным, может быть больше одного голоса на день, когда пользователь выполняет запрос. Чтобы гарантировать, что любые ожидающие строки будут объединены во время выполнения запроса, у нас есть два варианта:
- Использовать модификатор
FINALв имени таблицы. Мы сделали это для запроса количества выше. - Агрегировать по ключу сортировки, используемому в нашей целевой таблице, т.е.
CreationDateи суммировать метрики. Обычно это более эффективно и гибко (таблица может использоваться для других целей), но первый вариант может быть проще для некоторых запросов. Мы показываем оба ниже:
Это ускорило наш запрос с 0.133с до 0.004с — более чем на 25 раз!
ORDER BY = GROUP BYВ большинстве случаев столбцы, используемые в клаузуле GROUP BY преобразования материализованных представлений, должны совпадать с теми, которые используются в клаузуле ORDER BY целевой таблицы, если используются движки таблиц SummingMergeTree или AggregatingMergeTree. Эти движки полагаются на столбцы ORDER BY для объединения строк с одинаковыми значениями во время фоновых операций объединения. Несогласованность между столбцами GROUP BY и ORDER BY может привести к неэффективному выполнению запросов, плохим объединениям или даже несоответствию данных.
Более сложный пример
В приведенном выше примере используются материализованные представления для вычисления и поддержания двух сумм на день. Суммы представляют собой самую простую форму агрегации для поддержания частичных состояний — мы можем просто добавлять новые значения к существующим, когда они поступают. Однако материализованные представления ClickHouse могут использоваться для любого типа агрегации.
Предположим, мы желаем вычислить некоторые статистические данные для постов за каждый день: 99,9-й процентиль для Score и среднее значение CommentCount. Запрос для вычисления этого может выглядеть следующим образом:
Как и ранее, мы можем создать материализованное представление, которое выполняет вышеуказанный запрос по мере вставки новых постов в нашу таблицу posts.
В целях примера и чтобы избежать загрузки данных постов из S3, мы создадим дубликат таблицы posts_null с той же схемой, что и posts. Однако эта таблица не будет хранить никаких данных и будет использоваться только материализованным представлением, когда строки вставляются. Чтобы предотвратить хранение данных, мы можем использовать тип движка таблицы Null.
Движок таблицы Null является мощной оптимизацией - думайте об этом как о /dev/null. Наше материализованное представление будет вычислять и хранить наши сводные статистические данные, когда в таблицу posts_null поступают строки во время вставки - это просто триггер. Однако исходные данные не будут храниться. Хотя в нашем случае, вероятно, мы все же хотим хранить оригинальные посты, этот подход может быть использован для вычисления агрегатов, избегая затрат на хранение исходных данных.
Таким образом, материализованное представление становится следующим:
Обратите внимание, как мы добавляем суффикс State в конец наших агрегатных функций. Это обеспечивает возврат агрегированного состояния функции, а не итогового результата. Это будет содержать дополнительную информацию, чтобы позволить этому частичному состоянию объединяться с другими состояниями. Например, в случае средней величины это будет включать количество и сумму столбца.
Частичные состояния агрегации необходимы для вычисления правильных результатов. Например, для вычисления среднего арифметического просто усреднение средних арифметических поддиапазонов дает некорректные результаты.
Теперь мы создадим целевую таблицу для этого представления post_stats_per_day, которая хранит эти частичные агрегированные состояния:
В то время как ранее SummingMergeTree был достаточен для хранения счетчиков, нам требуется более продвинутый тип движка для других функций: AggregatingMergeTree.
Чтобы обеспечить ClickHouse знанием о том, что будут храниться агрегированные состояния, мы определяем Score_quantiles и AvgCommentCount как тип AggregateFunction, указывая функцию источника частичных состояний и тип их исходных столбцов. Как и в случае с SummingMergeTree, строки с одинаковым значением ключа ORDER BY будут объединены (в приведенном выше примере — Day).
Чтобы заполнить нашу post_stats_per_day с помощью нашего материализованного представления, мы можем просто вставить все строки из posts в posts_null:
На практике вы, вероятно, прикрепите материализованное представление к таблице
posts. Мы использовалиposts_nullздесь, чтобы продемонстрировать нулевую таблицу.
Наш окончательный запрос должен использовать суффикс Merge для наших функций (так как столбцы хранят частичные состояния агрегации):
Обратите внимание, что мы используем GROUP BY здесь вместо использования FINAL.
Использование исходной таблицы в фильтрах и соединениях в материализованных представлениях
При работе с материализованными представлениями в ClickHouse важно понимать, как исходная таблица обрабатывается во время выполнения запроса материализованного представления. В частности, исходная таблица в запросе материализованного представления заменяется вставленным блоком данных. Это поведение может привести к некоторым неожиданным результатам, если его неправильно понять.
Пример сценария
Рассмотрим следующую настройку:
Объяснение
В приведенном выше примере у нас есть два материализованных представления mvw1 и mvw2, которые выполняют похожие операции, но с небольшим отличием в том, как они ссылаются на исходную таблицу t0.
В mvw1 таблица t0 напрямую ссылается внутри подзапроса (SELECT * FROM t0) с правой стороны соединения. Когда данные вставляются в t0, запрос материализованного представления выполняется с вставленным блоком данных, заменяющим t0. Это означает, что операция соединения выполняется только над вновь вставленными строками, а не над всей таблицей.
Во втором случае с объединением vt0 представление читает все данные из t0. Это гарантирует, что операция соединения учитывает все строки в t0, а не только вновь вставленный блок.
Почему это работает именно так
Ключевое отличие заключается в том, как ClickHouse обрабатывает исходную таблицу в запросе материализованного представления. Когда материализованное представление активируется вставкой, исходная таблица (t0 в этом случае) заменяется вставленным блоком данных. Это поведение можно использовать для оптимизации запросов, но также требует тщательного внимания, чтобы избежать неожиданных результатов.
Сценарии использования и предостережения
На практике вы можете использовать это поведение для оптимизации материализованных представлений, которым нужно обрабатывать только подмножество данных исходной таблицы. Например, вы можете использовать подзапрос для фильтрации исходной таблицы перед объединением с другими таблицами. Это может помочь уменьшить объем данных, обрабатываемых материализованным представлением, и улучшить производительность.
В этом примере набор, создаваемый из подзапроса IN (SELECT id FROM t0), имеет только вновь вставленные строки, что может помочь отфильтровать t1 по этому критерию.
Другие применения
Вышеописанное в основном сосредоточено на использовании материализованных представлений для инкрементного обновления частичных агрегатов данных, таким образом перемещая вычисления с времени запроса на время вставки. За пределами этого общего случая использования, материализованные представления имеют ряд других применений.
Фильтрация и преобразование
В некоторых ситуациях мы можем пожелать вставлять только подмножество строк и столбцов при вставке. В этом случае наша таблица posts_null могла бы принимать вставки, с запросом SELECT, отфильтровывающим строки перед вставкой в таблицу posts. Например, предположим, что мы желаем преобразовать столбец Tags в нашей таблице posts. Он содержит список имен тегов, разделённых трубой. Преобразовав их в массив, мы можем легче агрегировать по отдельным значениям тегов.
Мы могли бы выполнить это преобразование при выполнении операции
INSERT INTO SELECT. Материализованное представление позволяет нам инкапсулировать эту логику в DDL ClickHouse и упростить нашINSERT, применяя преобразование к любым новым строкам.
Наше материализованное представление для этого преобразования показано ниже:
Таблица справки
Пользователи должны учитывать свои модели доступа при выборе ключа сортировки ClickHouse, используя столбцы, которые часто используются в фильтрах и агрегациях. Это может быть ограничивающим фактором для сценариев, когда у пользователей есть более разнообразные модели доступа, которые нельзя закодировать в одном наборе столбцов. Например, рассмотрим следующую таблицу comments:
Ключ сортировки здесь оптимизирует таблицу для запросов, фильтрующих по PostId.
Предположим, пользователь хочет отфильтровать по конкретному UserId и вычислить их средний Score:
Хотя это быстро (данные малы для ClickHouse), мы можем понять, что это требует полной проверки таблицы, исходя из числа обработанных строк - 90.38 миллионов. Для более крупных наборов данных мы можем использовать материализованное представление, чтобы получить значения ключа сортировки PostId для фильтрации по столбцу UserId. Эти значения затем могут быть использованы для выполнения эффективного поиска.
В этом примере наше материализованное представление может быть очень простым, выбирая только PostId и UserId из comments при вставке. Эти результаты отправляются в таблицу comments_posts_users, которая упорядочена по UserId. Мы создаем нулевую версию таблицы Comments ниже и используем её, чтобы заполнить наше представление и таблицу comments_posts_users:
Теперь мы можем использовать это представление в подзапросе, чтобы ускорить наш предыдущий запрос:
Цепочки
Материализованные представления могут быть соединены в цепочки, позволяя установить сложные рабочие процессы. Для практического примера мы рекомендуем этот блог.